Why I chose to read a book to learn Python
Are you interesting in starting to learn Python? I will show you a few resources, and the one I chose after a few pandemic experiences.


It was also written under the demand of no one, only as a matter of exploring my own interests.
Table of Contents:
Introduction
As Yuval Harari says in his book '21 Lessons for the 21st Century'[1] the role of Artificial Intelligence (AI) and Bioengineering will increase exponentially. And due to the fated nature of liberalism, we as humans may become gradually more useless if the government doesn't impose some control in data gathering and usage. However, I, in particular, don't feel very optimistic about my own government pursuing such topics. Therefore, that being one of the reasons why I want to further explore and improve my own knowledge within computational topics, I propose showing my learning path after trying some different options. Further, I will expose some topics in particular, which I didn't know properly and were useful in my everyday use. Finally, I highlight some projects that I will later explore, regarding the better use of data and a few aerospace applications.
Besides Harari's point, I did also choose to further enhance my knowledge in Python, because, after having shifted from Matlab/Octave, I perceived how poorly I was writing and structuring my own code. And even though I was able to reach the desired results within my thesis and undergraduate research, I saw room for improvement. I know that google searching for a similar problem solved in stackoverflow can provide me an answer. However, in the long run, my code won't be as succinct, as maintainable and repeatable as I would like it to be. Therefore, from a chat with my friend Gabriel, I decided to search and read an adequate literature.
Previously, I had already taken C computing classes in my undergraduate course, I have watched plenty of videos on programming, and done some free online courses. Firstly, out of those, I would like to highlight Fabio Akita's[2] recommendation of the Open Source Society University (OSSU). They have whole curriculums designed for a self taught path, including only free material. Two in particular are worth noticing, the Computer Science[3] and the Data Science[4] ones. Right in the beginning of the curriculums, the introductory courses usually require some knowledge in Python, and their recommendation is the Python for Everybody[5] (PY4E) course. Secondly, freeCodeCamp[6] is also noteworthy, there is plenty of material not only on their webpage, but also on youtube. For most of the learning paths they offer, you will be provided with the content and a compiler next to it, in order to directly apply what you have just learned. It is very engaging, because only one tab is required and the exercises and applications are done alongside the theory. However, the scientific computing with python[7] course redirects you to PY4E. Thus, showing the importance given by many sources to PY4E, which will offer a certification for you in the end. If you are willing to begin, it is a reasonable starting point.

Nonetheless, having to finish my undergraduate degree at home saturated me with obligatory videos to watch. Additionally, with the current state of technology that is continuously demanding our attention, I find it increasingly difficult to sit down and exclusively pay attention to a long video. Therefore, I was looking for other possible sources when I found out about Santiago's[8] recommendation: "Python Crash Course 2nd Edition"[9] from Eric Matthes. My main reason for choosing a book and a different learning method is due to my own methodology towards learning this topic in specific. First, my study sessions were sparsely distributed throughout the week. Secondly, I had to drop some sessions in order to prioritize other topics within work and studying. Therefore, I ended up forgetting some concepts, which are not easily retrievable in videos or in a compilation of short exercises from freeCodeCamp, for example. While reading the book at my own pace (not watching a video at 2x the speed), doing the exercises and taking my own notes, I found more success in keeping the knowledge. Eric Matthes provided a well rounded overview about the main introductory topics towards learning python, whilst providing exercises to consolidate the theory.
Below, I would like to present some of the topics that I didn't know previously and were useful to me. And later, show which are my next steps, project wise.
Learnings
The main objective for me to completely read and finish the "Python Crash Course 2nd Edition"[9] book was to better establish and build the foundations necessary towards scientific computing through Python, which is my primary focus. Therefore, I must correctly understand the usage of all types of data structures (from variables and strings to lists and dictionaries), be familiar with classes and functions, and implement conventional guidelines within my code to increase readability and maintainability.
1. Styling conventions (PEP 8)
Python Enhancement Proposal (PEP) aims to provide information and updates to the Python community, explaining new features, its processes or its own environment. PEP 8[10] in specific provides a style guide for Python code, and its main objective is to provide a base of conventions in order to improve the general understanding of the language (almost like a "grammar" book setting the rules, which should be followed, except if the code will break or become less readable).
The primary insight for PEP 8 is that readability counts. For example, the longer the program, the more readable it should be, in this way other people can understand the whole structure and reasoning behind the implementation more easily. Additionally, it will even improve the readability of your program to yourself, which is necessary because most of the time spent coding is by reading and not writing it (you'll probably write it once and read it many more times while testing and debugging, for example).
The general recommendations from PEP 8 involve code lay-out, whitespace usage, comments, naming conventions, etc. Out of those, I would like to highlight the general code lay-out suggested and the naming conventions (from variables to files).
PEP 8 suggests:
- 4 spaces per indentation (you should check if tabs are converted to spaces, and converted to how many of them, because otherwise, problems may arise within the files while mixing tabs and spaces);

- lines should have less than 80 characters (it is useful to add a ruler to your text editor) - main due to old terminal limitations;

- some of the naming conventions are as follows:
- variables should be in lowercase, containing only letters, numbers and underscores to replace spaces (e.g. variable_1, variable_to_do_something);
- constants should be in UPPERCASE with underscores separating words (e.g. CONSTANT_1);
- functions follow the same convention as variables, actually is the other way around 😅 (e.g. create_something_new(arg_1, arg_2));
- classes use CamelCasing, a capital letter every new word without underscores (e.g. NewClass);
- modules should have short and lowercase names, underscores can be used (e.g. learning_python.py).
And always keep in mind:
“However, know when to be inconsistent – sometimes style guide recommendations just aren’t applicable. When in doubt, use your best judgment. Look at other examples and decide what looks best. And don’t hesitate to ask!” - PEP 8
2. Strings
As simple as it may be, there may also be some methods and functionalities that you do not know. That was the case for me, I didn't know what f-strings and other string methods were, both of which enhance the interface with the user.
In python, anything inside single or double quotes is a string, additionally, it can be defined as a series of characters. Strings can be easily changed, for example, changing the casing type used and removing extra whitespaces. In order to execute those operations, Python provides built-in methods, some of them that are string related:
- string.title(), changes each word to title case, beginning with a “Capital Letter”;
- string.upper() or lower() - changes all characters to either “UPPER” or “lowercase”;
- string.strip(), rstrip() or lstrip() - removes whitespaces from both, right or left sides.
It also may be useful to create strings from other string variables. In that case, f-strings[11] come in handy, where variables can be inserted inside other strings (available since Python 3.6, currently 3.10.5 in June 2022). Its basic usage is by adding the letter f before the first quotation mark and putting braces around the variable you want to add. For example, a simple concatenation process could be switched to a f-string, as follows:
# declare the variables
first_name = 'stephen'
last_name = 'king'
# make the custom message
message = "Hello, " + first_name.title() + " " + last_name.title() "!"# declare the variables
first_name = 'stephen'
last_name = 'king'
# make the custom message
message = f"Hello, {first_name.title()} {last_name.title()}!"The output in both situations is: Hello, Stephen King!
Therefore, instead of concatenating all the necessary parts, in one line, we are able to format the string (f-string).
3. Dictionaries
Dictionaries are collections of key-value pairs, where every key is connected to a value, accessing and modifying a value through the respective key, for example. A key's value can be any sort of data (number, strings, lists, multi-dimensional arrays, etc). They are defined by wrapped braces, for example: dictionary = {key1: value1, key2: value2, ...}. One of their applications is to store one kind of information about many objects.
In my case, I was required to store different kinds of data for each iteration (each iteration would be my object mentioned above) of my numerical solution, including all instances of mesh, the solution itself, binary arrays to identify whether adaptive meshing was required, etc. Therefore, using dictionaries, I was able to store and analyze how and if my adaptive meshing was working correctly.
# save intermidiate results to dict_results
# the choice of a dictionary was mainly due to the lack of uniformity of the
# results (size(x) is different than size(xe), for example)
dict_results[str(iteration)] = {
'x': x_tmp_adpt,
'u': u_tmp_adpt,
'xe': xe_tmp_adpt,
'r2': r2_tmp_adpt,
'R2': R2_tmp_adpt,
'etaK': etaK_tmp_adpt,
}# calculate the error estimator again through the mesh - adaptive
xe_tmp_adpt = np.zeros((N_tmp_adpt-3))
r2_tmp_adpt = np.zeros((N_tmp_adpt-3))
h2r2_tmp_adpt = np.zeros((N_tmp_adpt-3))
R2_tmp_adpt = np.zeros((N_tmp_adpt-3))
hR2_tmp_adpt = np.zeros((N_tmp_adpt-3))
etaK_tmp_adpt = np.zeros((N_tmp_adpt-3))
for i in range(1,N_tmp_adpt-2):
# jacobian, in this case the h_K
B_e_i = x_tmp_adpt[i+1] - x_tmp_adpt[i]
xe_tmp_adpt[i-1] = (x_tmp_adpt[i+1] - x_tmp_adpt[i])/2 + x_tmp_adpt[i]
r2_tmp_adpt[i-1] = B_e_i
h2r2_tmp_adpt[i-1] = B_e_i**2*r2_tmp_adpt[i-1]
R2_tmp_adpt[i-1] = np.power((-u_tmp_adpt[i-1,0] + 2*u_tmp_adpt[i,0] - u_tmp_adpt[i+1,0]),2)
R2_tmp_adpt[i-1] += np.power((-u_tmp_adpt[i,0] + 2*u_tmp_adpt[i+1,0] - u_tmp_adpt[i+2,0]),2)
hR2_tmp_adpt[i-1] = B_e_i*R2_tmp_adpt[i-1]
etaK_tmp_adpt[i-1] = np.sqrt(B_e_i**2*r2_tmp_adpt[i-1] + B_e_i*R2_tmp_adpt[i-1])Some of the common operations are:
- to add new key-value - dictionary[new_key] = new_value;
- to start with an empty dictionary - new_empty_dictionary = {};
- to modify a value, using the assignment operator - dictionary[key_which_value_needs_to_be_modified] = new_value;
- to remove a key value pair - del dictionary[key_to_delete];
Finally, after storing all the information in a dictionary, you'll probably be required to access all of it. The easiest way is through for loops:
- for key, value in dictionary.items() - to access both, keys and values;
- for key in dictionary.keys() - to access just the keys;
- for value in dictionary.values() - to access just the values.
4. Functions
Within the whole first part of the book "Python Crash Course 2nd Edition"[9], the biggest takeaway for me to help improve my programming skills is to implement functions and to refactor (separate each process in smaller chunks) everything.
Basically, functions are blocks of code designed to do one specific task, consequently, if constantly required, your code will become more succinct, readable and easier to fix. And they return information (a value or a set of values), process data and/or both.
As mentioned in the introduction, after having shifted from Matlab/Octave, I didn't have the habit of creating functions alongside the construction of the overall structure of my code. Therefore, I ended up copying and pasting a handful of parts instead of creating a function, in order to execute tasks such as populating a rigidity matrix, solving linear systems, estimating the error, and so on. Furthermore, those tasks were not only executed for each iteration, they were also required to be executed for different types of meshes used (uniform and adaptive), definitely identifying a huge gap of improvement.
# matrices for the linear system Au = b
A = np.zeros((N, N))
b = np.zeros((N, 1))
# populate the rigidity matrix and the charge vector
# python utilises zero indexing
for i in range(0, N-1):
B_e_i = x[i+1] - x[i] # jacobian
A[i, i] = A[i,i] + np.power(B_e_i,-1)
A[i, i+1] = A[i, i+1] - np.power(B_e_i,-1)
A[i+1, i] = A[i+1, i] - np.power(B_e_i,-1)
A[i+1, i+1] = A[i+1, i+1] + np.power(B_e_i,-1)
b[i, 0] = b[i, 0] - B_e_i/2
b[i+1, 0] = b[i+1, 0] - B_e_i/2
# boundary values
# assure the boundary values readequating the rigidity matrix first
A[0, 0] = 1
A[0, 1] = 0
A[N-1, N-1] = 1
A[N-1, N-2] = 0
b[0, 0] = 1 # u(0) = 1
b[N-1, 0] = 1 # u(1) = 1
# solving the system, through u = A^-1.b
u = linalg.inv(A).dot(b)For example, all of the steps in the figure are repeatedly executed along all iterations. Usually, after the solution "u" is calculated, an error estimation is executed in order to proceed with the desired adaptive meshing, which will in the end provide a "new" domain. Afterwards, the process repeats creating the matrices which size corresponds to the previously obtained domain. A proposal to refactor just the initial process to find the next solution is as follows:
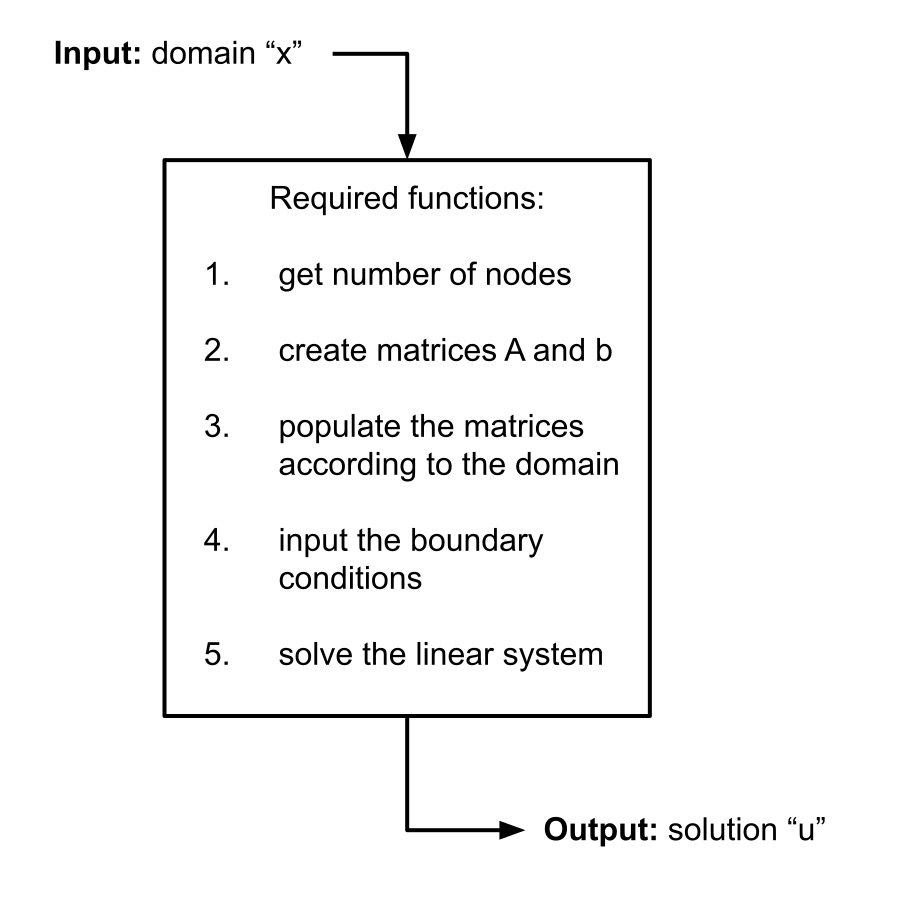
Additionally, some suggestions to better document and create the necessary functions are:
- PEP 257[12] which provides guidelines for one line or multi-lines docstrings (documentation strings)
# one liner
def function(parameter):
“””docstring “””
operation with the parameter
# multi-liner
def return_value_function(argument1, ...):
"""Returns the value required to solve the problem x.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do
eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim
ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut
aliquip ex ea commodobconsequat.
"""
operation
return return_value- functions are separated from the main block of the program:
- therefore, you can store them in a separate place or file (usually called modules);
- and afterwards importing them whenever necessary by:
- using the import statement.
5. Testing
Alongside the construction of the algorithm and the subsequent code, it is often necessary to implement a methodology to evaluate the cohesion among the results found throughout the evolution of your code. Therefore, tests can be implemented and are a proof that the code works and responds correctly to all defined types of input. Furthermore, Python provides a way to automate those tests to verify function's outputs and classes through the unittest[13] module.
Basically, you will be required to construct a test case, that is a collection of unit tests, each one of which verifies a specific output type of a function's behavior. The basic syntax is:
import unittest
from file_function import function
class FunctionTestCase(unittest.TestCase):
"""Tests for 'file_function.py'."""
def test_first_aspect(self):
"""suitable docstring"""
returned_value = function(arg_1, arg_2)
self.assertEqual(returned_value, expected_value)
if __name__ == '__main__':
unittest.main()Any method inside the FunctionTestCase (that inherits from unittest.TestCase) which starts with test_ will be automatically run. The outputs could either be passing or failing tests:
Passing test
.
----------------------------------------------------------------------
Ran 1 test in 0.000s
OKFailing test
E
======================================================================
ERROR: test_first_aspect (__main__.FuctionTestCase)
----------------------------------------------------------------------
Traceback (most recent call last):
(traceback description) ...
----------------------------------------------------------------------
Ran 1 test in 0.000s
FAILED (errors=1)The most important step when correcting the code after a failing test is to never change the established tests. From my perspective, I believe that I should also try implementing tests within my own programs, because throughout the execution of my undergraduate research, the only way I found to analyze if the results were correct was through manually calculating in Excel, which, of course, is far from ideal.
Finally, it is worth mentioning that among all topics f-strings, functions and testing are the ones I will try to implement right away.
Next steps
After finishing the theoretical part to correct and rebuild my Python foundations, I'll shift to a more project oriented study methodology. In the second part of Matthes' book[9], he presents three project options. However, for my objective of further pursuing scientific computing topics, the data visualization one is the most suitable. Additionally, there are also other projects for engineering students from Andrew Davies[14], that I want to try out. And lastly, after bumping into Juan Rodríguez's[15] LinkedIn profile, I found his masters degree thesis[16], which interests me to further explore aerospace topics.
To conclude, I would like to thank you for your company along the way, and I hope you can take something from my just starting learning path, which I plan on sharing the correspondent insights I get.
References
[1] Harari, Y. N. (2018). 21 lessons for the 21st century. Spiegel.
[2] Fabio Akita. (n.d.). Youtube. Retrieved June 28, 2022, from https://www.youtube.com/channel/UCib793mnUOhWymCh2VJKplQ
[3] OSSU. (n.d.-a). computer-science: Path to a free self-taught education in Computer Science! Retrieved June 28, 2022, from https://github.com/ossu/computer-science
[4] OSSU. (n.d.-b). data-science: Path to a free self-taught education in Data Science! Retrieved June 28, 2022, from https://github.com/ossu/data-science
[5] PY4E - python for everybody. (n.d.). Py4e.Com. Retrieved June 28, 2022, from https://www.py4e.com/lessons
[6] Alumni Network. (n.d.). FreeCodeCamp.Org. Freecodecamp.Org. Retrieved June 28, 2022, from https://www.freecodecamp.org/learn
[7] Alumni Network. (n.d.). Scientific Computing with Python. Freecodecamp.Org. Retrieved June 28, 2022, from https://www.freecodecamp.org/learn/scientific-computing-with-python/
[8] Santiago. (n.d.). Twitter. Retrieved June 28, 2022, from https://twitter.com/svpino
[9] Matthes, E. (2019). Python crash course (2nd edition): A hands-on, project-based introduction to programming. No Starch Press.
[10] PEP 8 – style guide for python code. (n.d.). Python.Org. Retrieved June 28, 2022, from https://peps.python.org/pep-0008/
[11] 2. Lexical analysis — Python 3.10.5 documentation. (n.d.). Python.Org. Retrieved June 28, 2022, from https://docs.python.org/3/reference/lexical_analysis.html
[12] PEP 257 – docstring conventions. (n.d.). Python.Org. Retrieved June 29, 2022, from https://peps.python.org/pep-0257/
[13] unittest — Unit testing framework — Python 3.10.5 documentation. (n.d.). Python.Org. Retrieved June 29, 2022, from https://docs.python.org/3/library/unittest.html
[14] Davies, A. J. (2022, April 4). 5 Python projects for engineering students. Towards Data Science. https://towardsdatascience.com/5-python-projects-for-engineering-students-8e951b7c131f
[15] Rodríguez, J. L. C. (n.d.). Juan Rodríguez’s profile. Linkedin.Com. Retrieved June 29, 2022, from https://www.linkedin.com/in/juanluiscanor/
[16] Rodríguez, J. L. C. (n.d.). pfc-uc3m: Final degree project: Study of analytical solutions for low-thrust trajectories